
工具概述
CyberTask 是一套爬虫系统,用于分布式的利用计算机的 CPU 和网络资源从中心服务器拉取任务并本地执行,然后将结果上报到服务器,此系统提供了一套失败重试机制,提供了 Clojure/Java/Go 爬虫客户端支持,亦包括一套 Web 界面展示任务状态。
其工作机制如下所示:原始的数据集(Excel、数据库数据等)通过 Clojure REPL 或 REST API 导入到服务器,作为一个任务集,然后启用多个爬虫客户端,定义其工作逻辑:爬虫首先从服务器拉取一或者多条任务,拉取时承诺多少分钟内返回结果,然后执行逻辑,获取结果后上报服务器。如果爬虫因为各种原因离线,则其拉取已分派的任务在指定时间未完成,则回收到任务集重新派发给其他爬虫,如果此爬虫后续恢复,则此条任务结果根据配置选择覆盖或忽略。值得一提的是,系统在导入数据时可配置失败次数,如果多个爬虫多次尝试均失败,则超出失败次数后此条任务将不会被重新拉取以节省计算资源。
系统提供了一个 Web 界面,展示当前任务集的状态,包括在队列中、成功或失败的条目数,其自动刷新并实时展示队列数据。当全部爬取结束后,允许从中央服务器下载任务集结果。
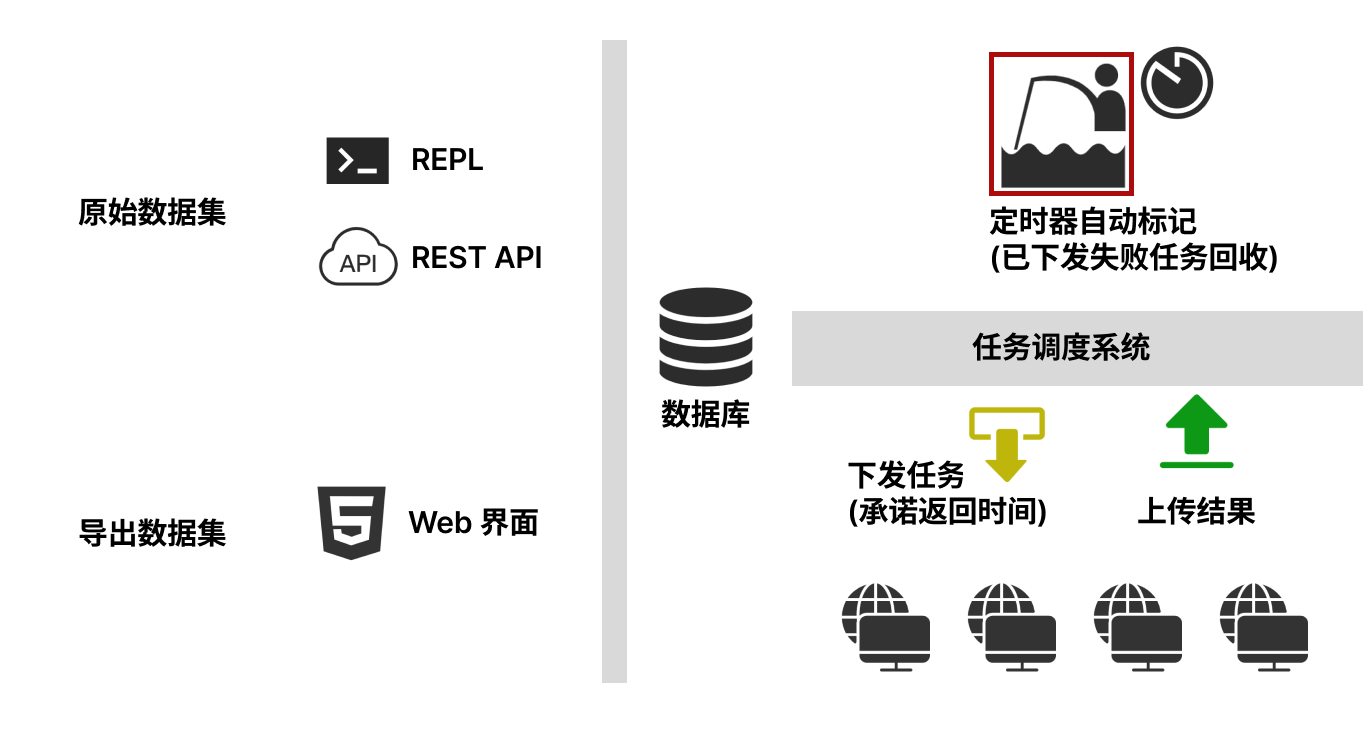
本系统提供了 Clojure/Java/Kotlin/Scala/Golang 等编程语言 SDK 和 REST API,方便实现异构爬虫,在不同的平台上利用计算资源爬取数据。
客户案例
下面是此工具爬虫的一个客户案例:其基于 Clojure 脚本,使用 etaoin 库,通过 geckodriver 驱动 Firefox WebDriver 实现无头浏览器页面控制,通过服务商的 Socket 5 代理访问目标网站,通过服务商的基于 Python 和 OpenCV 的图像识别服务实现滑块控制,通过模拟用户输入、滑块验证的方式完成登录、数据查询和爬取操作。
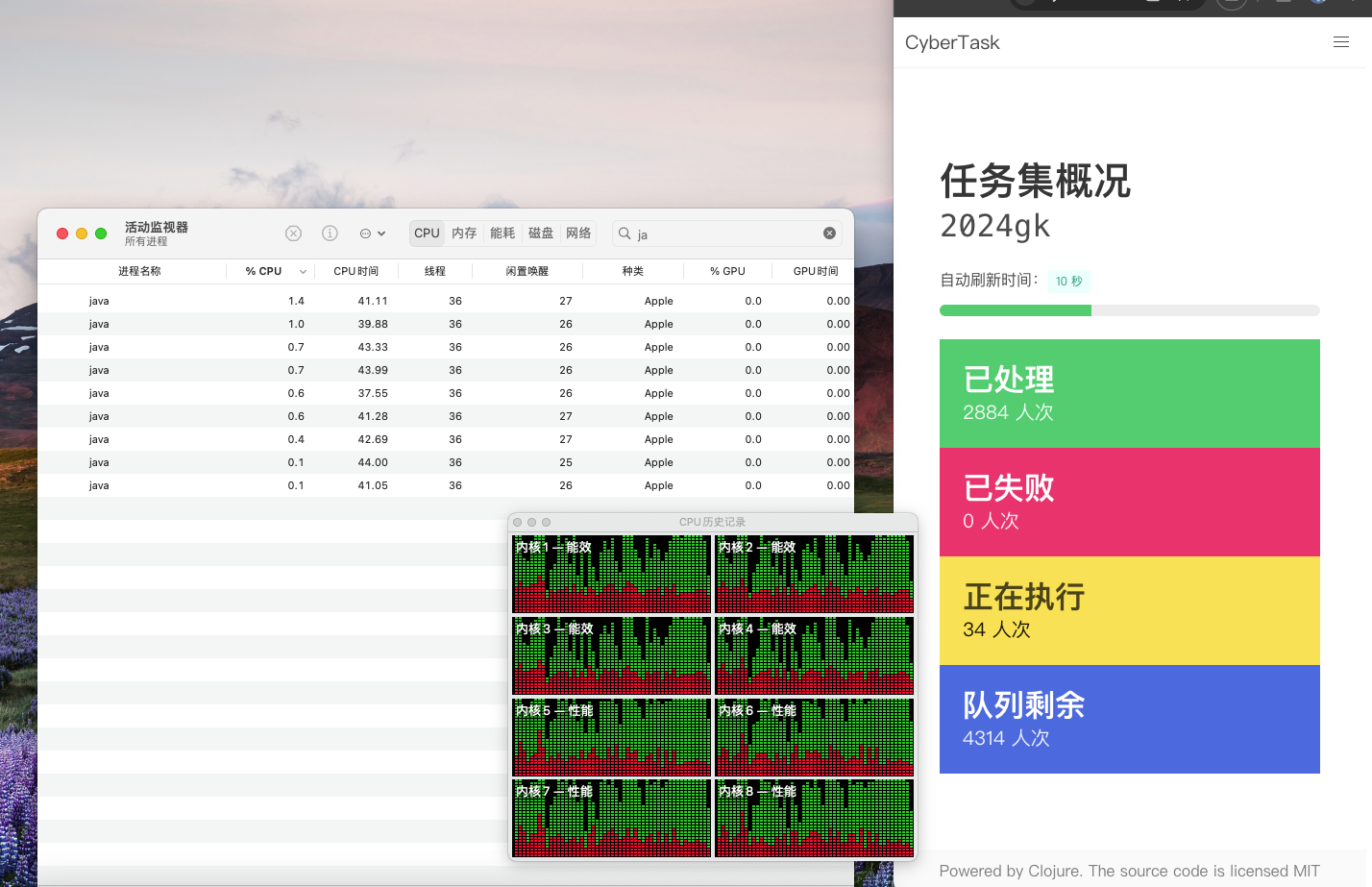
客户收益
相比较脚本直接编程的方式,此平台提供了一种通用且任务无关的方式来分发和回收数据,更为重要的,定义并实现了失败资源的重试和放弃机制,以实现更好的系统冗余和健壮性,使得爬虫的编写更为简单。
在此客户多年的爬虫开发、维护中,系统已提供数十万次的任务分发请求,未有失败者。根据客户反馈,这一系统的关注点分离使得根据爬虫目标网站维护爬虫代码的工作量大大减少,提升了数据收集的效率,极大的增强了业务开发的敏捷性。