GAI:最伟大的直觉
不要再试图让大语言模型替你进行深度思考了。
在过去两年深度折腾各类效率工具、整理待办数据与账单的过程中,我逐渐摸索出面对 AI 最恰当的姿态:把它当成一种“伟大的直觉”。
这是一种极其宝贵却又充满不确定性的能力。伟大,在于它跨越了个体认知的边界,快如闪电地帮你完成模式识别、扫清认知摩擦力;直觉,则意味着它同样会不知何时就自信满满地信口开河。
面对这种伟大的直觉,我们该如何去“用”?我的答案是放弃全盘托付,转而驾驭它,围绕它建立一套去伪存真的个人生活工作流。落到具体操作层面,无非是“用、验、纠、通”四个步骤。
一、系统 1 的寄生与我的四个“直觉入口”
丹尼尔·卡尼曼把人的思维分为两类:系统 1 是直觉,快如闪电,不费力气,擅长模式识别,但也满是偏见;系统 2 是理性,缓慢沉重,需要刻意启动,负责检验和修正。大语言模型出生的那一刻,我就隐约觉得它天然是系统 1 的寄生体——只要给它喂足了上下文,它总能在我们还没想清楚问题时,就给出一个像模像样的答案。
所以我开始把它嵌入日常系统,不求它绝对正确,只求利用它强大的瞬间直觉。
-
第一个入口,在我的工作日历上。 上个月做加班统计,我把工作日历的粗略数据喂给系统,它瞬间算出了进度:目标进度 10.7/40 小时,并贴心地提示“工作日还需加班 29.3 小时,平均每个工作日 5.9 小时”。这种“秒出”的模式识别能力,是任何人类系统 1 都难以企及的。更妙的是,它甚至能觉察到这种高强度加班不可持续,主动建议我根据时间安排将大头挪到周末,以对冲工作日的压力。

-
第二个入口,在我的书房里。 以前研读经典,遇到评价两极分化,去搜索引擎找答案是个极易打断心流的过程。现在,我在系统里建了一个“AI 问书”。点击的瞬间,系统已在后台将书籍元数据作为 Context 静默注入。它能结构化地向我剥析,南怀瑾《老子他说》的争议,本质上是“经史合参”的通俗解读与严谨学术考据之间的冲突。
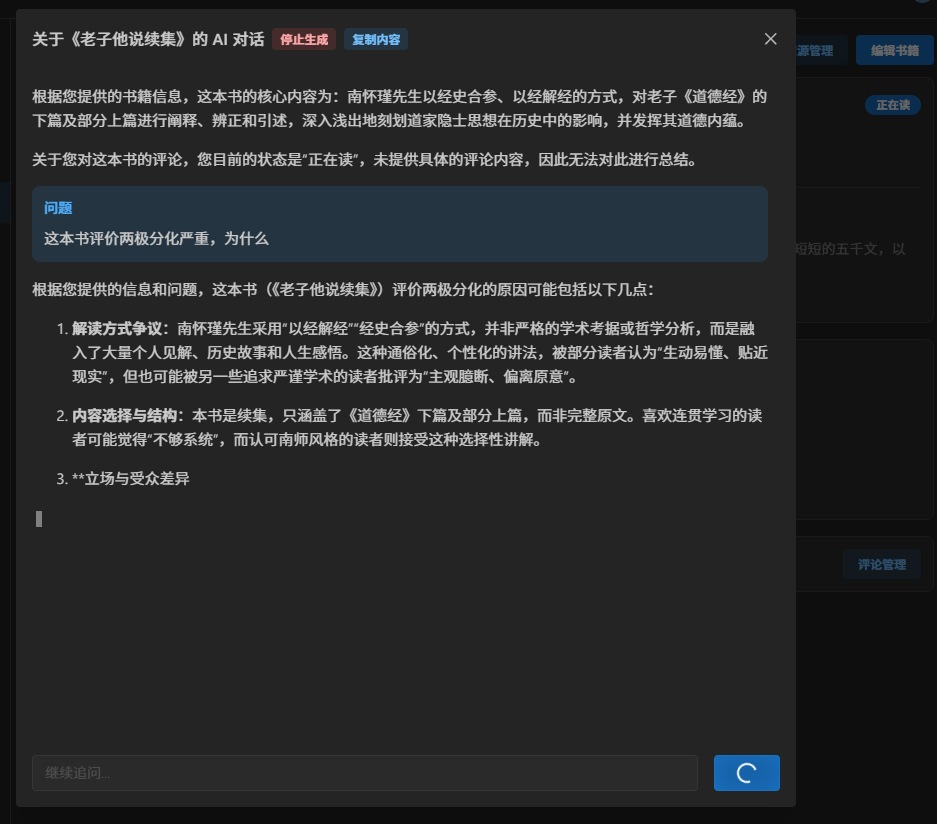
-
第三个入口,在我的家庭药箱前。 面对生病时的用药焦虑,这套系统同样能提供瞬间的决策支撑。当我分不清“风寒”还是“风热”感冒颗粒时,呼出“AI 问药”,它能凭直觉瞬间生成一张对比表格。从核心病机、典型症状到舌象脉象一目了然,将晦涩的医学说明书转化为了普通人能看懂的行动指南。
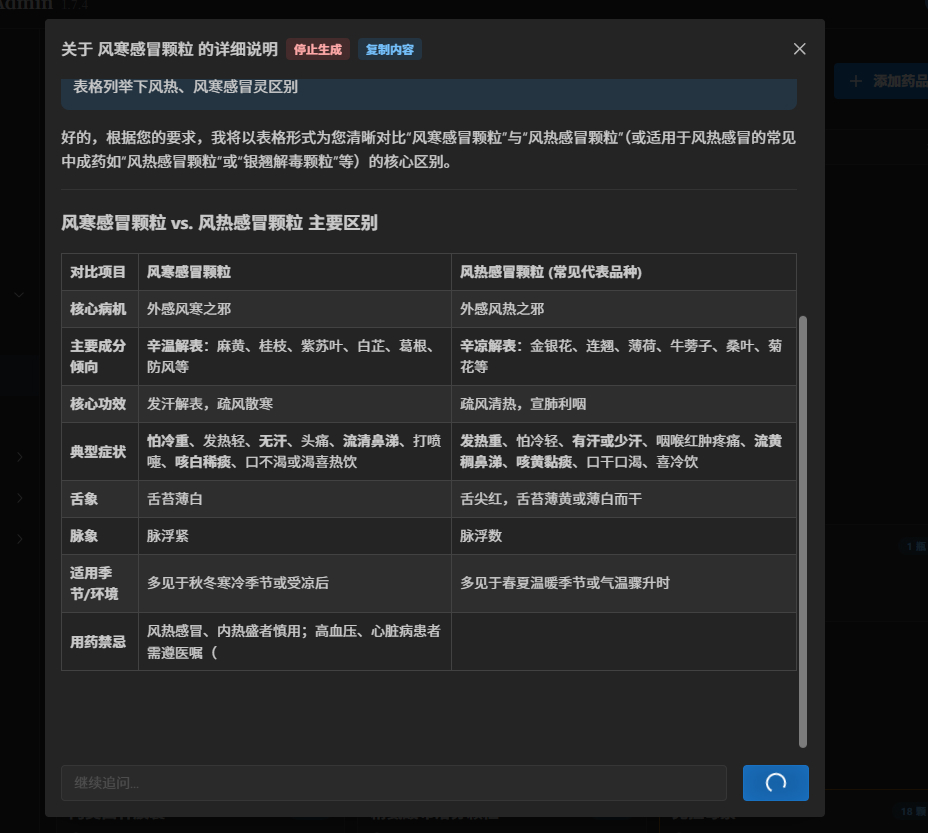
-
第四个入口,在我的财务账单里。 面对繁杂的信用卡流水,我写了一套带提示词的 JSON 导入器。哪怕只是截一张账单图片扔进去,AI 强大的视觉直觉也能根据我过往的分类习惯,自动将“小象超市”归为“餐饮”,把“滴滴”划入“交通”。这省去了我手动清洗、对齐数据的无尽烦恼。
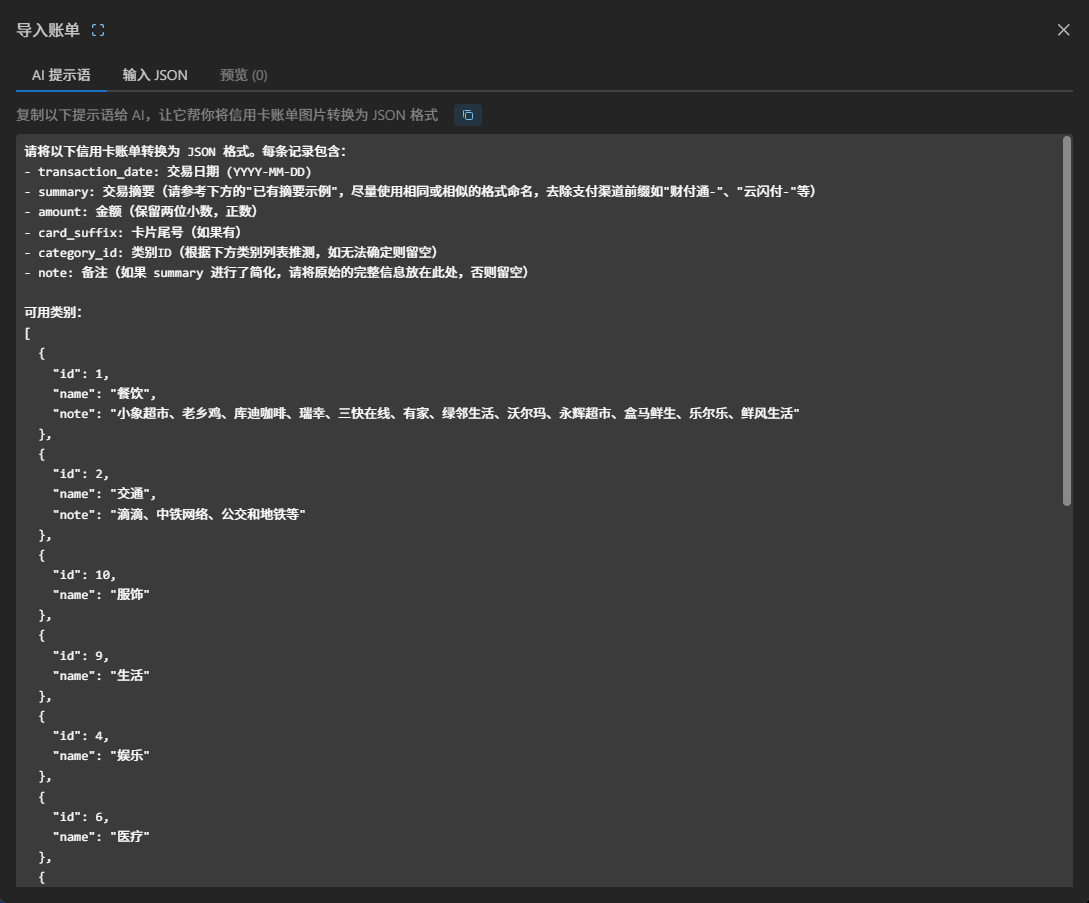
二、技术变迁:从补全到文本 Skill,一场关于上下文的回归
我是怎么实现这些入口的?这些实践并非凭空产生,它们精准地踩着大语言模型技术演进的节拍。这段不算长的历史,其实就是一部“上下文主权”的争夺与回归史。
最早是补全 API 的时代。GPT-3 的 text-davinci-003 只能接收和输出纯文本。你要小心翼翼地把指令和示例揉进一段长文里,像古代方士念咒炼丹一样,求得一个未必靠谱的回话。上下文全靠手工拼接,极其笨重。
随后进入 Function Calling 时代。模型开始感知外部世界,不再直接输出答案,而是生成一段 JSON 指令交由外部函数执行。这看似给系统 1 装上了手脚,但随之而来的问题是:它经常选错工具、填错参数。对于生态而言,函数调用的权限、格式和规范太过苛刻。那种适合精确代码的 API,并不适合主要依靠概率预测来回答问题的 LLM。带着镣铐跳舞,只会让它离“直觉”的本意越来越远。
再往后,MCP 登场,试图为所有工具制定统一标准,让模型像操作系统一样挂载外设。幻想很丰满,实则过于沉重。仅仅为了读取一个本地文件,就要搭建一套标准的服务端,这彻底违背了系统 1 的轻量化原则——最好的工具调用,应当如呼吸般自然,而不是像启动一台精密仪器般繁琐。
兜兜转转,于是便有了近期基于文本 Skill 赋能,通过 CLI 直接调用本地生态的 Agent 模式。模型不再生成 JSON 去调用繁琐的函数,而是按需读取技能文件,通过终端原生执行的命令行输入输出来实现生态交互。在这里,文本既是思考,也是行动。用户无需封装厚重的 API,一段精准的 Prompt 就能让 LLM 利落地完成“把账单截图转为规范 JSON”的任务。
这不仅仅是技术的做减法,更是一种哲学层面的回归:一切皆文本,一切皆对话与上下文工程。
三、四步实践:在直觉之上架起理性的桥
面对这股庞大但野性的直觉力量,经过无数次试错后,我摸索出一个四步循环,专门用来“调教”这个系统 1,让它尽量向真实靠拢。
第一步,用:一次性投喂完整上下文。
不再跟 AI 漫无目的地闲聊,而是把任务、数据、规则打包成结构化的 Prompt。比如我的待办导出功能,设计初衷就是为了导出指定日期内的完整 JSON 元数据(保留日期、列表、标题、时间)。我可以直接把这些干净纯粹的数据投喂给外部更强大的大模型,去做深度的周报分析。上下文越完整,它的直觉越精准。
第二步,验:把 AI 的产出当成初稿,永远不信任它。
每次导入账单,AI 虽然能自动清洗,但我知道它有时会偷懒(比如把“盒马鲜生”误判进“生活”类)。我必须对着那张支出分布的饼图逐条核对。这一步毫无技术含量,却是“去伪”的关键。直觉再惊艳,不经检验也不过是漂亮的幻觉。
第三步,纠:将修正经验沉淀回提示词。
发现“盒马鲜生”是餐饮不是生活?没问题,我就在提示词的类别规则里,把它硬编码进餐饮那一行,确保下次 AI 不再犯错。这种持续反馈,就像在给系统 1 持续打补丁。纠错的本质,就是把系统 2 的理性思考,重新编码进系统 1 的直觉网络里。
第四步,通:让直觉在工具链里自动流淌。
待办数据导出成 JSON,账单清洗后进行可视化分析,再交由外部工具生成报告。我用统一的格式化文本,把 AI 嵌进日常的每一环工作流中。直觉由此不再是一次性消费品,而成了可以管道化、自动化的底层基础设施。
四、内核:独立思考才是系统 2
把 LLM 当作系统 1 的“伟大的直觉”,确实极大延展了我的认知边界和处理效率,但我始终铭记卡尼曼的另一句警告:系统 1 是“自动运行的,你无法随意停止它”。
LLM 也是如此,它给出的答案常常自信满满、细节丰满,却极可能是一本正经的胡说八道。因此,再强大的直觉,也需要一个“不信任它”的人在旁边盯着。那个人,就是我的系统 2——独立思考的自我。
去伪存真,去的是 AI 直觉里的幻觉与虚妄,存的是经得起跨领域验证、逻辑推敲的内核。这个过程,与南怀瑾先生讲《老子》时强调的“经史合参、以经解经”不谋而合:不盲从一家之言,而是多方参究,找到那个直指真实的东西。
说到底,无论技术怎么迭代,工具怎么演进,我们面对 AI 的姿态,始终应当像一个谨慎的骑手,驾驭着一匹感知力超群、但也容易受惊的烈马。伟大的直觉赋予了我们一往无前的速度,但唯有独立的思考,才能确保我们抵达正确的地方。