一种爬虫思路:越过 Cloudflare 保护
背景
我的服务平台需要访问 HCM 系统 API 以获取打卡数据,需要访问 Microsoft Todo 以获取待办事项,需要访问 Exchange 以获取最近邮件,并从中解析和 12306 订票相关的内容,需要访问天气数据以提供下雨提醒,需要访问资源站以提供美剧更新提醒。这些第三方服务五花八门,除了 Microsoft 对自己的服务提供了 Graph API 和统一的 OAuth 认证、彩云天气、Apple Weather 有商用 API 外,其他供应商的认证方式多是针对终端用户的 —— 它们并不想让客户离开自己的“孤岛”,因而故意通过登录手机号验证、滑动验证码或者 Cloudflare 保护以阻拦和防止第三方应用对用户信息的获取。
我在稍早时候介绍过一种利用 Headless 浏览器模拟用户登录,通过截取滑动验证码到 OpenCV 后端服务获取滑动量并鼠标模拟滑动的方式获取网页数据的思路,加上供应商提供的 IP 代理地址池,可以以几乎无限的速率获取网站数据。基于这一技术实现的分数爬虫已经多年为我服务 —— 但这种方式总是在本地开发环境运行的,低频次需求。
在最近几年的微服务化进程中,我通过将 Chrome 浏览器和 WebDriver 封装为 Docker 镜像的方式,通过内置的 JDK 和 Clojure 运行时,通过映射脚本实现可移植的爬虫,我把这一套系统部署在自己的虚拟机上,因为运行频次很低,所以大部分时候还好,但每次运行,基本都导致 100% 的 CPU 占用和内存飙升。
直到我遇到了函数计算。
其实函数计算并不是什么新鲜玩意,在云原生之前,各个云平台就有这样的 SaaS 服务,不过当时受限于运行环境的标准化不足,大部分供应商只提供少数语言和框架的支持,并不灵活 —— 直到现在,阿里云的 Serverless 平台的 Web 应用还仅支持少的可怜的平台和旧掉牙的 JDK,不过时髦的是加入了基于 Git 仓库的自动集成。
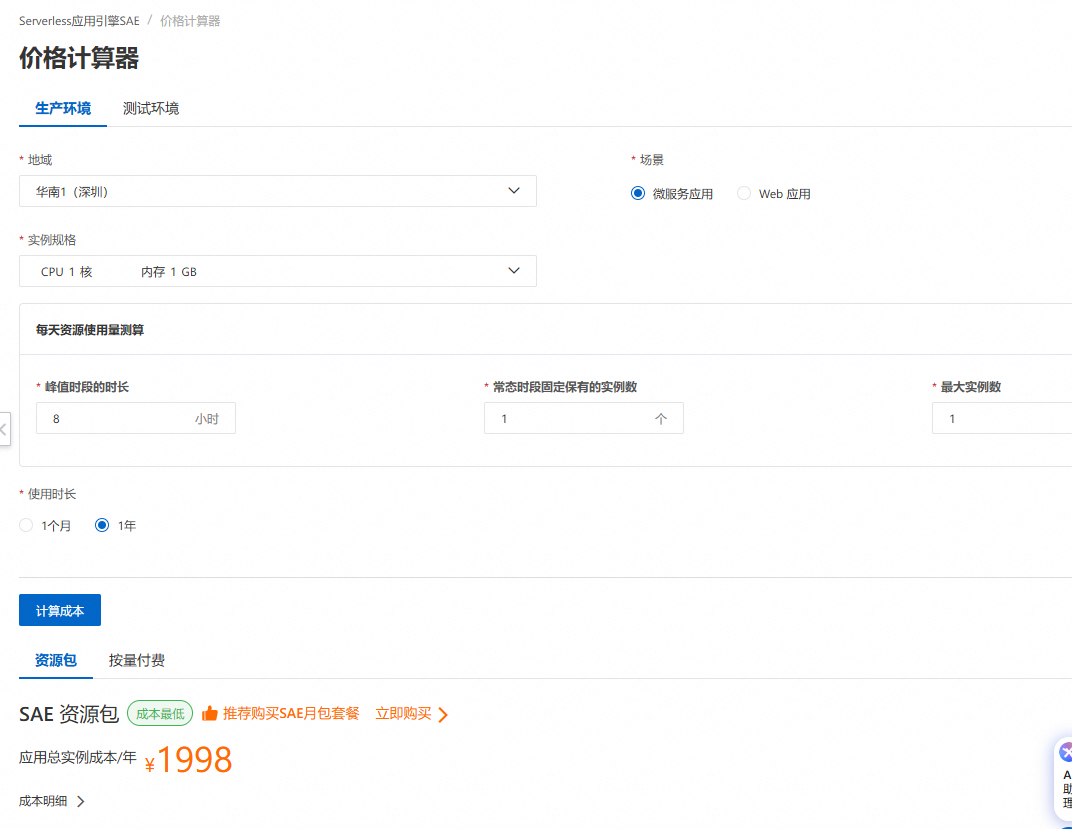
随着 Container 技术的大范围普及,各种云托管的容器服务开始流行,小到函数计算、微服务应用,大到完全托管的 Kubernetes 集群,甚至是 Kubernetes 舰队。不过,也不知道是计算成本还是网络成本而或是开发成本的缘故,这些基于容器的平台服务费用都贵的吓人,一个 1 核 1GB 内存的服务,按照每天 8 小时峰值运行,暴露一个公网 IP 路由,在阿里云最便宜的 Serverless 平台 SAE 上,一年的成本在 2000 左右,作为对比,1 核 1GB 内存的轻量应用服务器,抢购价能做到 38 每年。因此我选择基于这些跨云的小机自己搭建 Kubernetes 集群,自行搭建 Prometheus 的日志、指标和追踪可观测系统,通过 Rancher 管理集群,实现 GitOps 自动化部署,我的 12 核心 32GB 内存的集群,一年的成本在 500 元左右,这属实是用时间换成本了 —— 搭建、调试和处理 Kubernetes 集群花费了我极大的精力,但在云供应商这里,鼠标点一点,几分钟就出来了,附带开箱即用的监控、追踪和日志系统,还有云数据库、对象存储等各种服务可直接集成。
回到正题,我没有想到云平台的函数计算能够如此便宜,几乎为 0 的成本,就可以让远在千里之外的服务器自行调度容器,执行任务并返回结果,将业务系统和这些复杂、易错、容易变更的爬虫彻底分离,实现解耦。
我一开始封装了 Firefox 和 Geckodriver 的 Docker 镜像,以及内置编译好的 JDK 和 Clojure 脚本的 JAR 包,直接运行,但输出是一个问题,因此我通过参数传递了一个 URL,每次执行脚本结束后都回调它并上传数据。这个容器用于爬取网站的美剧更新数据,由于 Cloudflare 保护,花了一些精力屏蔽 Webdriver 特征,由于保护是通过监控用户鼠标行为、点击、滚动等 DOM 事件判断的,模拟这些事件过于复杂,且不稳定,因此每爬取一个网页就需要销毁 Webdriver 和浏览器实例。这个版本的第一次改动是,我将传入的 URL 的内容作为入参,通过一个字段提供了回调 URL,其余字段提供需要爬取的网页地址,通过这种方式实现了动态内容的爬取和上报。
当然,爬取逻辑还在容器封装着,但我明明使用的是 Clojure 脚本,作为最动态的编程语言,这种做法太大材小用。于是第二次改动是,将 Firefox、Geckodriver 或 Chrome 和其 Webdriver 以及 JDK 和 Clojure 运行时及几个 JSON、HTTP、WebDriver 库的依赖打包成 JAR 进行封装,通过一个极其简单的 Rust 程序从入参获取 URL 并执行并获得需要执行的 Clojure 脚本,然后调用 JVM 执行此脚本内容,至于参数和回调,就彻底不需要了,直接在脚本处理,这种方式极大的提升了这套爬虫系统的灵活性,也降低了维护成本。脚本不仅能静态存储在数据库、对象存储中,甚至还能动态通过服务器 API 拼接和生成。
我实现了一套增删改查脚本的 API 和其 Flutter GUI 界面,只需要为容器指定脚本名称,就能够配置好爬虫任务,至于说应用逻辑,可以随时修改脚本内容实现。
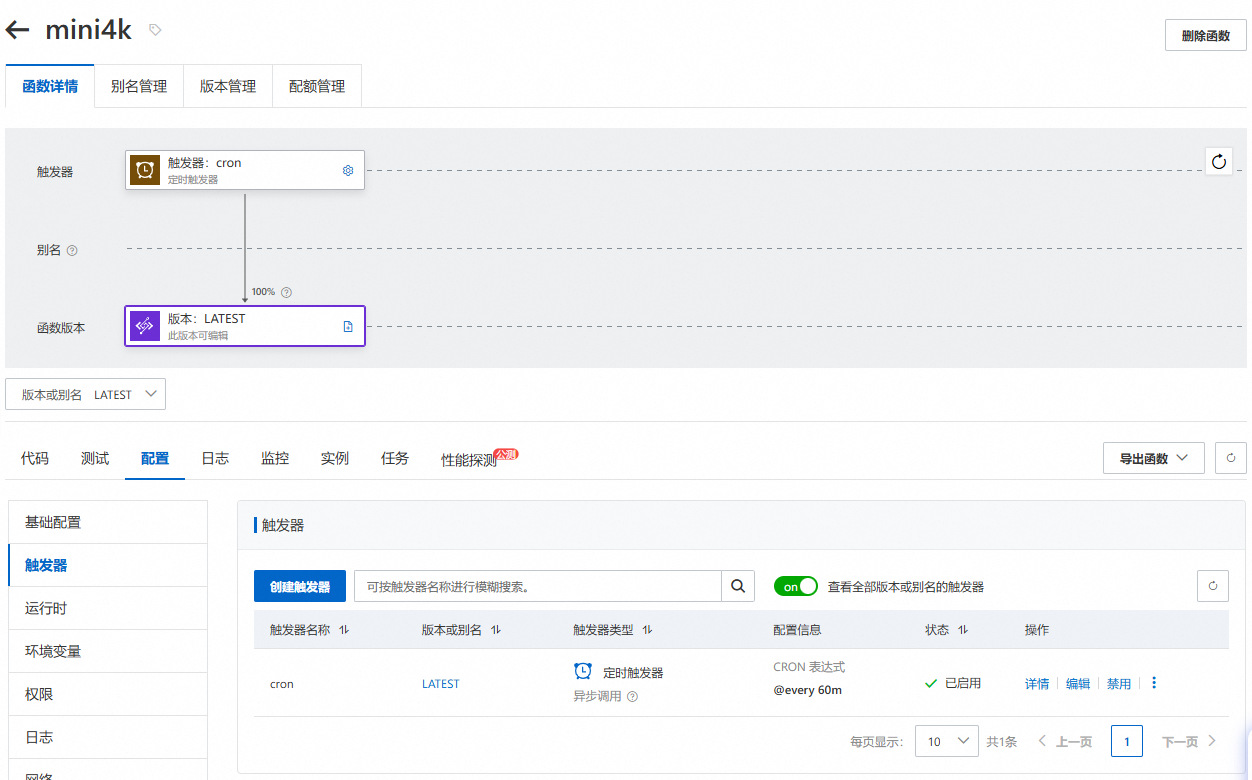
最后提一句触发逻辑,阿里云函数计算 FC 支持非常丰富的事件触发机制,我常用的有 HTTP 调用、定时任务和 OSS 特定目录下文件的变更。对于爬取美剧更新,定时任务就可以了。此外我还需要在自己维护的 HCM 系统 Token 过期时触发任务登录系统并通过 DevTools 获取 Cookie 并解析 Token,因此我通过使用向 OSS 特定目录下上传文件的方式触发调用。注意,为什么我封装了 Firefox 和 Chrome 两套环境 —— 因为虽然 Webdriver 提供了模拟用户操作、执行 JS 的标准 API,但 Chrome 支持更深的私有 API,包括打开 DevTools 获取执行日志,获取 Cookies、Headers 等内容,这对于爬虫来说可能是必须的。
美中不足的是,阿里云 FC 的产品经理似乎很无厘头,不仅在 Web 应用中误导用户,让用户将 Spring Boot 应用扔进来作为“函数”(实际上,一段时间没有 HTTP 调用后,环境会被自动回收,再次 HTTP 调用会利用缓存重新创建环境 —— 如果你使用 SQLite 等数据库,会发现它总会隔一会自动重置),还对基于容器的函数计算场景理解很不足,它们可能在对标友商特性的时候并不亲自使用并正确理解用户需求,竟然莫名其妙的认为所有容器都应该是 Unlimit 运行的 Web 类应用,实在是过于狭隘。实际上,所谓函数,就是给定输入返回输出,仅此而已,函数不可能是一个 Web 应用,也不应该是一个无限运行的后台服务,它应该是短暂的、用完即丢的标准化计算环境、逻辑和实例。
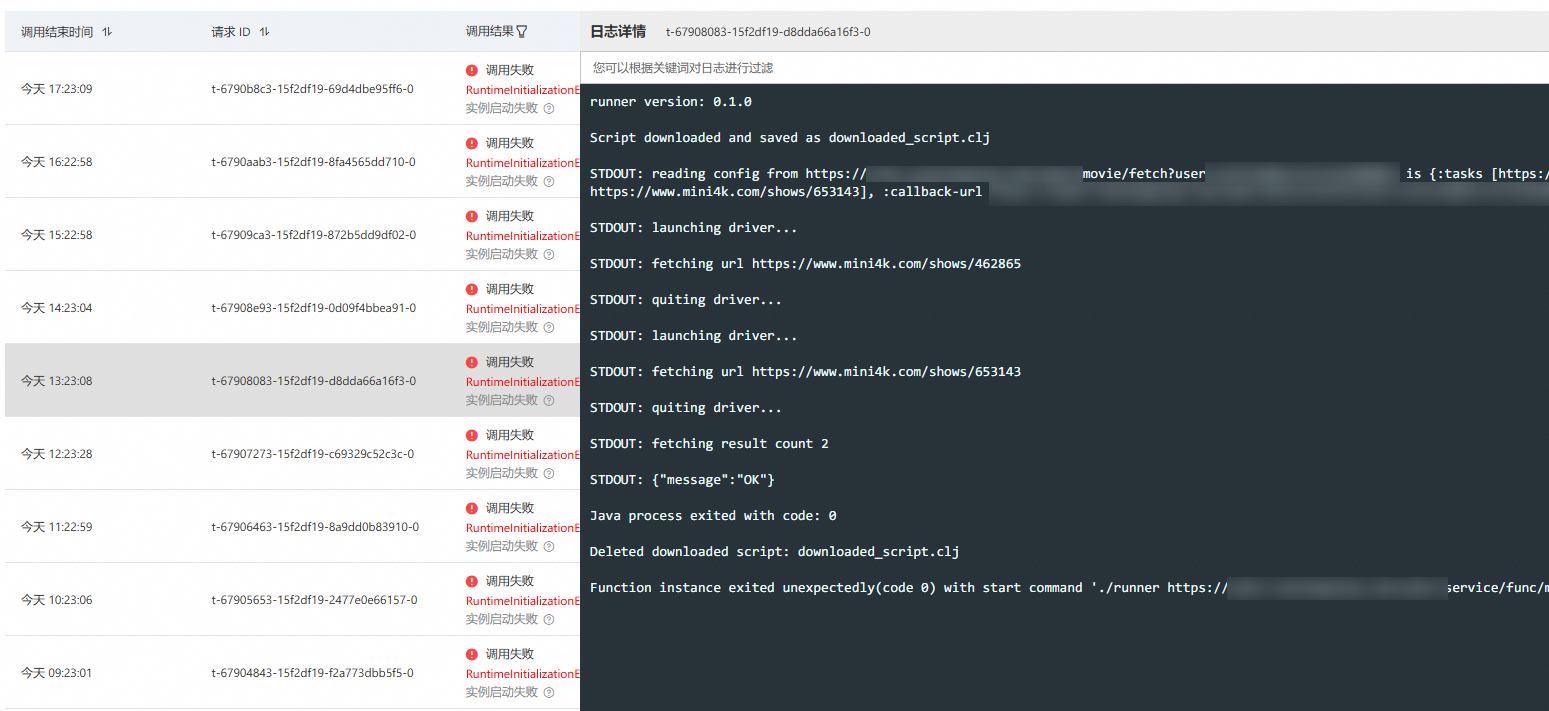
但我也没打算反馈工单给他们,毕竟失败的调用不计入开支(大概率是,起码是一部分开支)。