对 Clojure 云原生可观测性的思考
在这样的时间节点,已经没有人再去讨论 JVM 应用云原生的最佳实践了 —— 云原生深刻的改变了 JVM 平台的演进,包括且不限于 JDK 11 开始引入的基于 cgroup 的对容器内存和 CPU 资源的探测,值类型、虚拟线程、GraalVM 的 AOT 等等。开发者现在的选择不仅限于 Quarkus 这种为云原生而设计的框架,甚至还包括了 Spring,使用框架内置的编译插件,可以轻松的创建容器以及 AOT 化的容器。
从这个角度看,Clojure 好像反应更慢一些,年末将要发布的 1.13 版本才跟上 JVM 的脚步,才处理完 Monitor Lock 并换用 ReetrantLock 以避免虚拟线程的调度争用问题,虽然这并不太影响性能。而多年前的明星项目,Storm 也渐渐消失在人们的视野中,热度不在。虽然社区基于 GraalVM 的 SVM 搞了一个 babashka 出来,但争议一直存在,很多基于 JVM 的库不能很好兼容 AOT 生态,从这一点上来看,Clojure 面临和 Spring Framework 类似的问题 —— 但区别是,Clojure 社区似乎对于云原生并不热衷,让 JVM Clojure 生态迁移到 AOT 的难度,远比把基于每种主流 Native 语言写一个 Clojure 解释器并迁移标准库的难度大得多。
热更新
早在 Kubernetes 之前,我就一直在探索无中断的 Clojure 应用部署办法,苦于虚拟机的内存限制,这个想法一直未能成行,大部分时候,我选择直接触发代码更新并借助 clojure-reload 动态加载代码实现无中断的更新,但这偶尔会遇到问题,比如增加新的依赖,或者进行大规模重构,以及修改了后台定时服务逻辑,这时就不得不重启进程,被迫停机。迁移到 Kubernetes 之后,出于惯性,我为 Clojure 应用创建了伴生的 nREPL Deployment,但平常不部署,当需要热更新或者在线 Debug 时才连接到 Clojure 服务并执行操作。但经过一段时间后,我发现直接重新部署 Clojure Deployment 来的更方便 —— 我为这个 Pod 创建了一个 Rust 写的 initContainer,每次都会拉取最新代码并启动 Leiningen,得益于 Kubernetes 内置的 Deployment 滚动更新机制,新 Pod 会在启动和就绪探针成功后才杀死旧 Pod,这样就可以实现不停机更新了。大部分时候,我更新代码更多采用这种方式,这是我觉察到的第一个云原生上的改变。
流量入口、配置
Day0 的变化不仅如此,我使用 ConfigMap 为 Clojure 应用的配置文件进行了挂载,使用 Secret 存储各种服务的 JWT 密钥,这都是老生常谈的话题。此外,介于现在砍掉了 OpenResty 网关,而我的 Clojure 应用为多个 API 端点提供服务,所以我需要设置 Traefik Ingress 路由、配置各种 Prefix 前缀、限流中间件,以实现外部流量通信。Kubernetes 提供的声明式 CR 极大的简化了这一过程,统一存储的 Basic Secret 和 TLS Store 极大的降低了管理证书和凭证生命周期的繁琐,一次部署即可在多个工作节点的 Traefik DaemonSet 生效,轮换 Let'sEncrypt 证书的步骤被大大简化了。
服务拆分
我的 Clojure 应用在很早就进行了微服务拆分,但过去更多是基于手动管理,HTTP 通信,包括将需要拉起 Chrome 模拟访问爬虫的功能拆分为新容器,将网关、限流和鉴权转移到 OpenResty 中,将 MQ 生产者处理程序拆分为单独的 Quarkus 应用等等。在 Kubernetes 中,更多的功能都是通过容器实现,我在短时间内就创建了多个容器服务,包括 GeoAPI 提供 IP -> 城市 GPS 位置转换的服务,CalibreAPI 提供 Calibre 数据库 -> HTTPS API 数据的服务,BackupAPI 读取 Rclone mount 自动更新的配置文件,为 CronJob 中的 rclone 容器提供备份数据权限的服务,不一而足。
监控和观测
Prometheus Stack 通过 Kubelet、KubeProxy、CoreDNS、Metric Server 等提供了很多 Kubernetes 指标和面板,加上 Traefik 本身提供的流量入口指标,已经能够形成丰富的监控数据了:
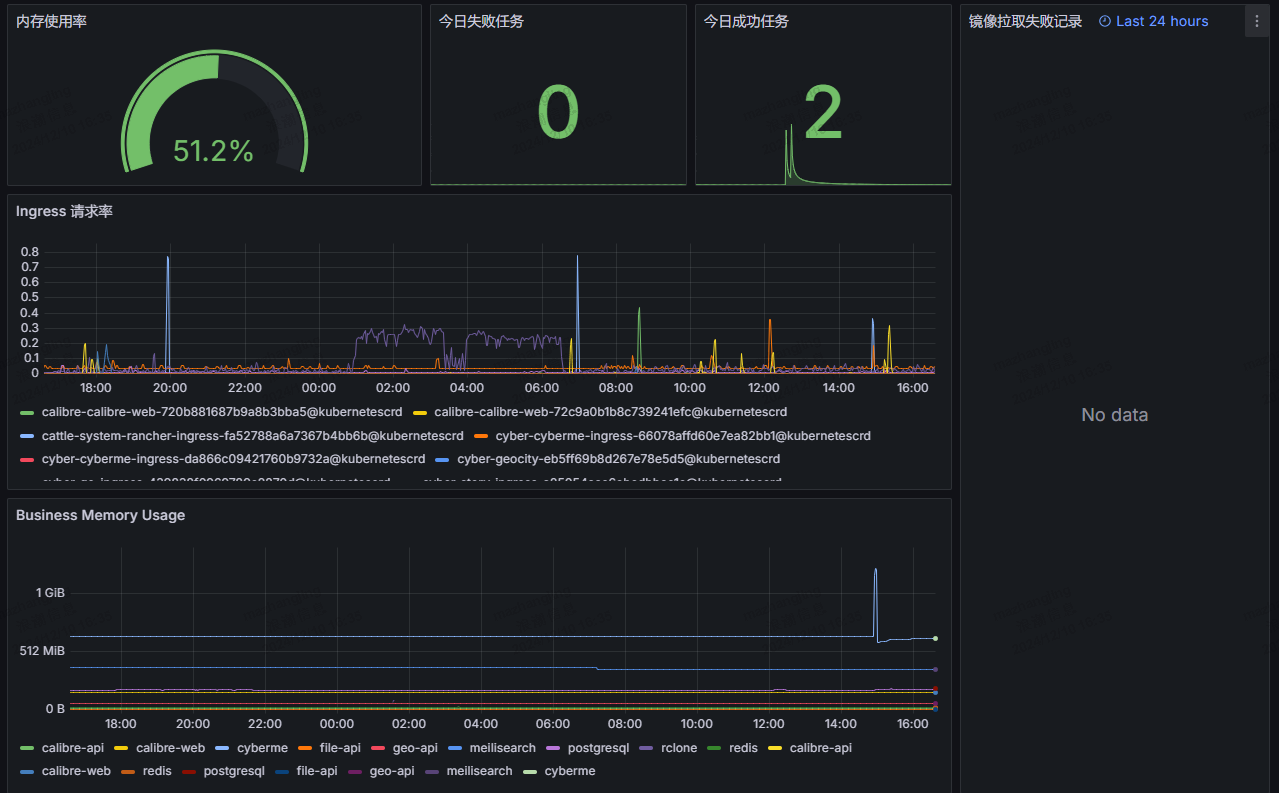
配合 Grafana Alerting,能够实现及时的告警,这对于保持集群健康来说至关重要。
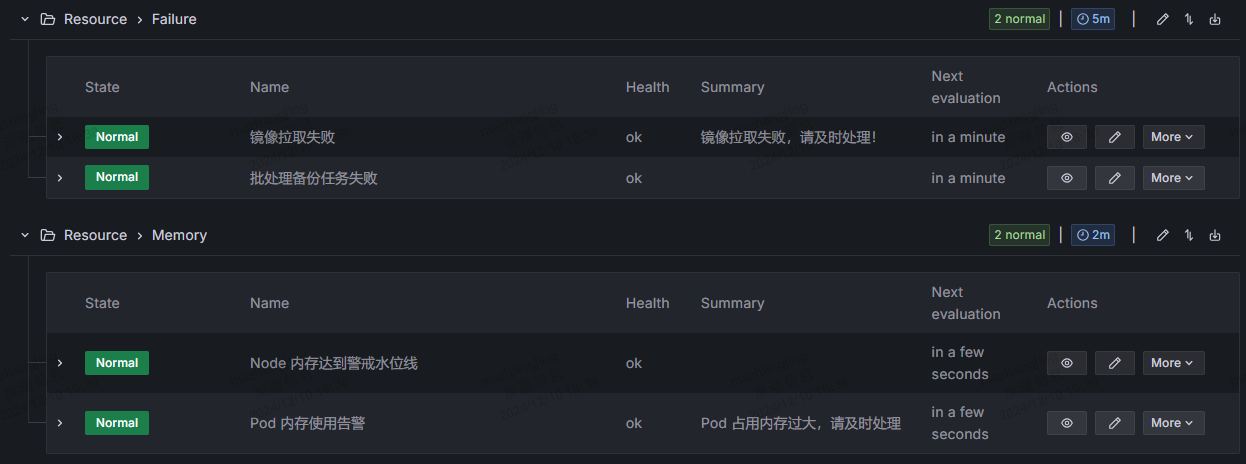
但可观测性不止如此,Day1 以来,我主要增加了业务的可观测性支持。主要通过为 Clojure 应用引入 iapetos,配置了 /metric 的抓取端点,增加了对 JVM 指标:包括 GC、内存、CPU、线程指标的监控,同时集成了 Ring Middleware 中间件,整合 Reitit 路由库输出 HTTP 错误、耗时和计数指标,同时修改 Path 为 Reitit Match 的路由模板,增加 Swagger Tag 作为标签。最后通过创建 ServiceMonitor CR 让 Prometheus Operator 自动发现并抓取这些数据。
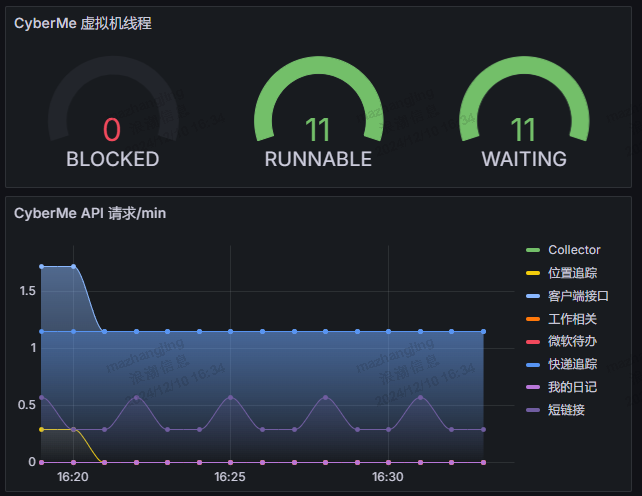
当数据就绪后,在 Grafana 中创建 Dashboard 展示这些数据,并创建 Alert 告警规则,在内存激增、GC 压力过大时触发告警。此外,对于 HTTP 指标的监控让我能够直观地看到不同 API 路由的请求耗时和错误率,基于此针对性的优化路由 handler 的代码实现,利用缓存提高可响应性。
Prometheus 适合时序数据,对于指标收集和监控很方便,但其要求较少的属性和简单的值,对于一些需求来说不能很好的满足。Loki 提供了基于 Kubernetes API Server 的对于 Pod 日志的集中化收集、存储和查询,其擅长对于非结构化的日志数据进行解析处理,适合短期数据的挖掘,比如定位某个接口行为逻辑,监控最近服务日志中的报错等问题。我基于 Loki 创建了很多仪表盘,包括对于最近错误的展示,以及最近请求故事系统的城市 IP 记录,以在地图进行可视化,并展示最近时间维度的请求率,以动态调整限流的阈值。可观测性的目的在于让开发人员采取行动,就这一点来说,我基于 Loki 的指标优化处理了多个第三方接口请求超时报错的日志,并根据故事访问情况优化了限流阈值。
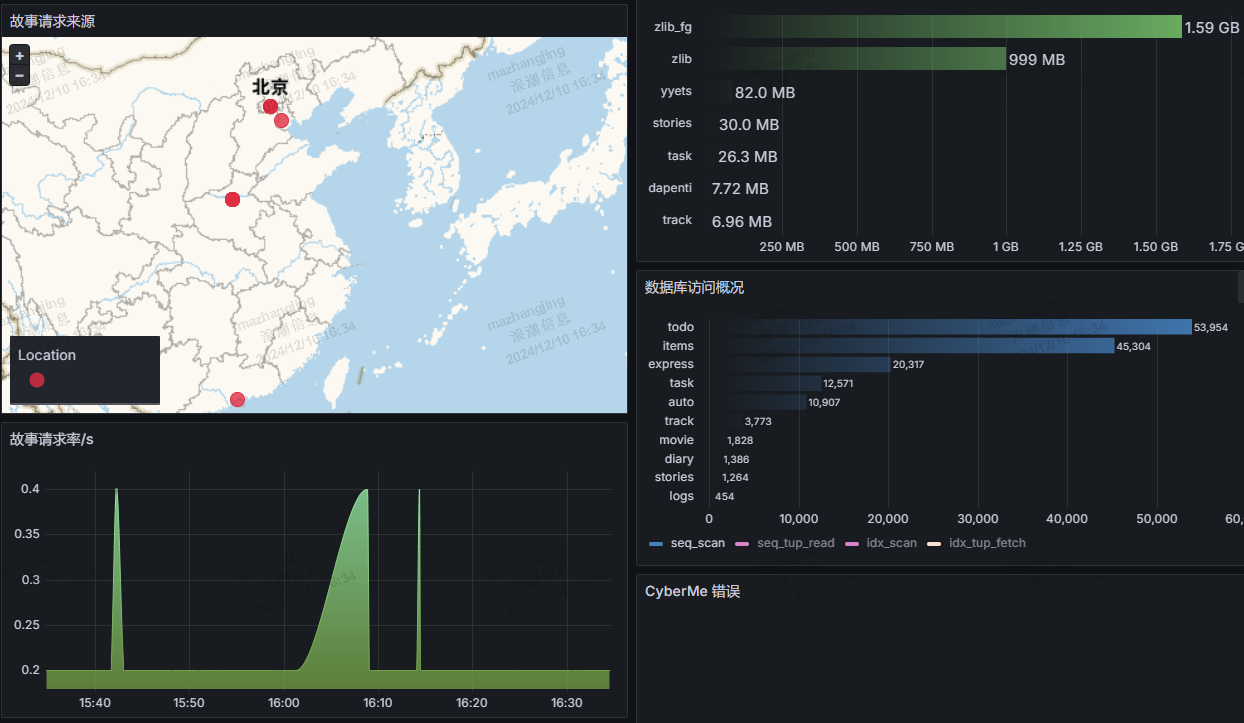
但可观测性不止如此,Prometheus、Loki 甚至是 Tempo 虽然覆盖了指标、日志和追踪,但这对于灵活的业务需求来说,可能并不够。Grafana 支持多种数据源,包括我最常用的 Redis、PostgreSQL 和 HTTP,我用于接入 Clojure 服务背后的数据库和 Clojure 服务提供的可观测性 API 本身,这进一步提升了灵活性。比如,基于 Redis,我通过创建复杂的 Lua 脚本实现服务的最近用户访问记录查询并根据服务分组展示为表格,基于 PosgreSQL,我通过创建 SQL 查询实现对于最近实验数据的检索并展示为表格,基于 HTTP,我直接利用现成的代码逻辑返回对各个接口调用计数数据的采集并可视化在 Grafana 的 Dashboard 中。
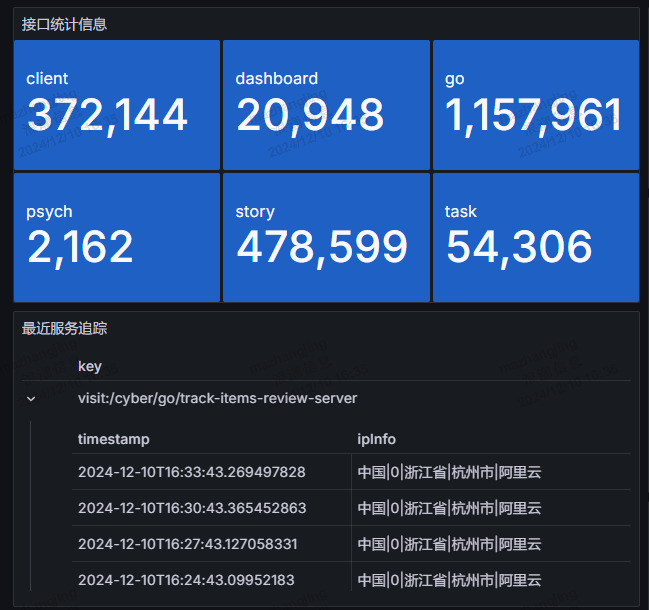
总体来说,我对 Clojure 应用的云原生化是满意的,但也有遗憾之处:较高的内存使用让我不得不顾及边缘集群的压力,因此很多服务我都选择使用 Rust Web 框架来实现,跨语言对于 Kubernetes 本应该是最友好的,但这仅限于 HTTP 和标准的同步和异步调用方式,比如 Kafka 或者 gRPC,像是很多 Clojure 生态的工具,比如 carmine,将其 MQ 实现迁移到 Java 上已实属不易,更不用提迁移到 Rust 上。
总的来说,云原生对于 Clojure 算不得上友好,很多时候,做事情的第一方式我已经很难再考虑到 Clojure,但一旦我需要编写一些 Clojure 代码,那种熟悉的、简单的、优雅又有乐趣的高表现力感觉瞬间就回来了。谁知道呢?或许我们应该对 Clojure 抱有一些期待,又或者,Clojure 基于的 JVM 本就不应该是做任何事情的最佳方式。但我始终相信,它总会找到自己的一席之地,不管是在过去、现在还是未来,都是如此。