我的云原生实践:Docker 篇
自从大三在学校图书馆随手翻起那本 我的第一本 Docker 书,到现在已经有 7 个年头,第一次读到容器技术,它带给我的那种惊喜的感觉还历历在目。不过在过去这么多年里,我却很少用到它,可能唯一的交集就是自己鼓捣的那台 UnRaid NAS 中装过几个 Docker 容器,了解过一些基于 Linux 网桥的网络实现,仅此而已。
对于大部分的技术和工具,使用者必须站在一定的视角下,在面临特定的工程问题的需求或困境下,才能够意识到一种技术的特点,并最大限度的发挥这些技术和工具的价值。
Docker 和 Kubernetes 就是这样的技术,更宽泛的讲,OpenStack 也是,换言之,整个云原生的技术堆栈,都是如此。当采用一种自顶向下的视角,了解、学习和评价这些技术的人们总会发展成为一种对这些特定技术工具的宗教信仰,毫无缘由的诋毁类似的技术和其他“宗教”信徒。常见的骂战包括 PHP vs Node.js, Java vs Go, Java vs .NET, Java vs Python 的语言战争,MySQL vs PostgreSQL 的 RDBMS 战争,MongoDB vs MySQL vs PostgreSQL JSON 的 KV 数据库战争,Redis vs Memory Map/Guava Cache 的缓存战争,Vue vs React.js 的框架战争,Block vs Async vs CSP 的响应式战争,手工部署服务 vs Docker 容器部署 vs Kubernetes 编排 vs Istio 服务网格的运维战争等等,典型的就是刚毕业的计算机类专业学生,会将 C++ 看做神一般的语言,并且傲慢的认为其余的语言都是平庸的垃圾。而另一些人,则秉承着“技术仅仅是一种工具”的理念,在对战的帖子下面也总是能够看到这样和稀泥的角色,我更愿意将这种人的态度看做以问题为中心的“自下而上视角”。实际上,这部分人中的一部分,大概率是仅仅道听途说过类似的技术,由于自己没有真正的去参与和实践过其中的一种方案,因此便没有形成宗教性的狂热,而另一部分,则是对不同的技术都有过研究和实践,并且能够在合适的场景下选择合适的方案,因此也没必要卷入这种技术宗教战争中去。
在我看来,不论自上而下还是自下而上的视角,这都是逐步采纳一种技术的不同发展阶段,从不知道,不了解到欣喜的发现某项技术能够完成某种任务,才会给技术赋予“自我实现”的价值,才能让技术变成一种宗教,才会对“异教徒”如此的不宽容以至于要对骂和打架的地步。如果对技术没有任何的热爱,是不可能成为一名宗教的信徒,而恰恰是成为信徒,才能够促进问题的解决以及自我价值的实现,甚至,不同的技术栈对人生轨迹的影响也是不同的:编程语言是一种使用技术看待世界的抽象描述,不同的视角决定了看到的世界将会是完全迥异的,处在这种世界中的人行动和思考的方式也是不同的,命令式和函数式思想就是绝佳的例子。其他的工具也有类似的效果,经常和 RDBMS 打交道的人会被强迫按照行列的模式来思考数据,而当他们处在一个完全由 KV 组成的世界,再成熟老练的开发者也会像刚毕业的菜鸟一样惊慌失措,技术是一种宗教,带着特定看待世界和解决问题的视角,这是一种模式,一种解决相似问题的利刃,当然也是一种束缚,一种条条框框的悲哀。因此,只有从狂热中冷静下来的人才能够回过头去,带着自己的体验,平静的看待技术所带来的以及所剥夺的东西。
我更推崇采用自下而上的视角来看待技术,从手头遇到的问题出发,探索解决这些问题的不同方案,坚持“开卷有益”,多看,多做,多尝试,这样才能够更全面的利用不同的技术,让其更好的完成自己的目标。换言之,正如同 SICP 的开头语:“成功计算的钥匙并不掌握在某个程序员手上,我们需要掌握的并且应该掌握的, 是一种智慧:看到机器比第一次站在它面前时能做的更多的能力。”
因此,在我看来,评价一门技术,首先要问自己:这门技术,在自己手中,是否能够推进自己目前所做的事情,以至于通过探索、实践和应用这项技术后,自己是否会站在一个更高的位置,有更大和更宽广的视野,来让机器在自己手中更好的、做更多更有趣的以及之前无法达到的事情。
对于我而言,采用 Docker 完全是一种迫不得已的选择:我一开始维护了一个用于自动化繁琐生活、工作的一个 Web 应用,叫做 CyberMe,它采用 Luminus 框架搭建,后端采用 PostgreSQL + HugSQL + Ring Middleware + HTTP Kit + Reitit Router + Lein + Clojure 实现,前端采用 Bluma + Shadow-cljs + React.js + re-frame + ClojureScript 实现。
这个服务大部分接口都是提供给 Web 前端,以及我的 iOS CyberMe App,Android CyberMe App 使用,且用户就我一个人,因此通常的开发迭代也很简单,前端 Web App 直接使用一个脚本,本地改完后测试无误直接打包上传到阿里云 OSS 即可自动生效,而后端则比较多样,对于简单的特性,通过 REPL 直接 eval 更新的代码直接编译为字节码在运行中的 JVM 中立刻生效,对于复杂的特性以及含有重构、后台服务更改、添加了新的依赖的情况下,则需要 Git 拉取代码并重启 JVM 以生效,我写了一个简单的脚本来自动化实现这些。
随着这个应用涉及到的内容越来越多:整合我的 Microsoft ToDo 待办,Outlook 邮件,Apple WeatherKit 天气,彩云天气,快递追踪,美剧追踪,喷嚏图卦更新推送,Slack 整合,Sendgrid 邮件服务,OSS 上传和下载服务,Wireguard 配置管理,日记管理,运动和健身管理,打卡管理和提醒,磁盘和 Calibre 图书管理,物品管理等,这套模式都能很好的应对,其中有几个模块我添置了一些内存缓存,有些内存缓存还蛮重要,比如存储 Microsoft Graph API 的登录和刷新 Token,我不想每次重启 JVM 都重新 OAuth 获取这个 Token,因此也添置了一些简单的钩子,在 Shutdown JVM 的时候持久化这些缓存到文件,启动时再读取。
随着开发频次的增多,以及模块的增多:12306 最近车票管理,体重管理,周计划和长期计划管理,应用管理等,线上内存和开发机的内存差异导致的一些问题越来越棘手。典型的,比如我在内存中放了 ToDo 待办事项列表 ID 和其中文名映射的 Map,以及 HCM Token,在本地开发时,由于本地没有这些内存数据,因此开发环境就不得不面临一些和线上环境表现不同的情况:所有待办都找不到列表名,HCM 频频提醒我找不到 Token 无法获取当前工作时长,虽然我知道这是因为在开发环境才会出现的问题,但过度依赖人脑对于软件开发而言绝对是一件坏事。
引入 Redis 为我很轻松的解决了这个问题,分布式内存缓存意味着开发机可以直接连接到生产 Redis 数据库,这样本地环境和远程环境就完全一致,这里利用到了 Redis 内存缓存的”分布式“特性。
当然,Redis 的可玩性还有很多,我的 CyberMe 实际上提供了一些公开服务,比如一个可以阅读童话故事的”故事社“网站和 API 服务,一个我用来跳转短链接的服务,这些服务在公开时,我一度很担心它们是否会遭到攻击和滥用,以至于拖垮我的数据库。我尝试在 Nginx 层加了一些缓存,套过 Cloudflare,但 Nginx 缓存太不灵活,而 Cloudflare 虽然可以基于 JS 来定制行为,但访问速度非常感人,引入 Redis 后,我不仅去除了所有的内存缓存,使得应用更加”无状态“化,并且自己写了一套 Ring 中间件,用来记录这些公共服务的访问 IP、统计热点 URL,用于为不同路由提供不同的缓存策略,以及各种模式的限速等:比如天气要基于请求的城市缓存,而故事接口则要根据用户 IP 和访问的故事限流,我甚至还通过 Redis 的键命名空间和事件的 Pub/Sub 模式实现了一个对于公共服务特定路由监控的功能,只需要在前端 Web 界面选择想要监控的路由,CyberMe 就会从订阅的所有 Redis URL 访问中过滤出来我们感兴趣的那些 URL,并且发送 Slack 告知这个 URL 最近被访问过。
总的来说,Redis 缓存极大的增强了我公共站点的安全性,像是后端渲染的模板,耗时函数和数据库请求的缓存等都重度依赖 Redis,此外,作为高性能临时数据库,我基于 Redis 实现了请求限流、Token 存储、日志记录,以及访问数据聚合统计等功能,此外,我也试图利用 Redis 巧妙的数据结构:ZSet 和 Set 实现了简单的分词和搜索功能,基于 Pub/Sub 特性实现了对于 Redis 写入特殊键日志的监听并通知用户,实现了通知消息的防抖,避免同样消息在同一时间频繁推送。
而最近,我基于 Redis 的 Lua 脚本尝试了微服务的分布式锁以及 MQ 特性:因为 CyberMe 毕竟是开发环境,一些公共服务总是因为 JVM 启停而受到影响,也不是很好,所以就将这些公共服务拆分到了 Quarkus 和 Node.js 微服务中,为了避免 Quarkus App 和 CyberMe 的 RPC 出错,因此一些功能,比如 CircleCI 推送 Docker 镜像后的 WebHook 事件会通过 Quarkus 应用 HTTP 端点接收,然后放入 Redis 的 Queue 中,CyberMe 会消费 Queue 的数据,用来持久化数据。
而微服务也是需要维护的,因此在微服务拆分的同时,我也学习了 OpenResty,并且使用 Lua 改造了 Nginx 网关,购置了通配符 SSL,动态的根据 Redis 的配置来决定访问流量是如何在微服务和 CyberMe 之间路由和负载均衡的,这保证了在所有的情况下,微服务提供的公共接口都不会中断,而 CyberMe 提供的服务在重启 JVM 时则由上一个版本的,限制了内存使用的备胎处理,每次停止JVM前都会拉起这样一个临时备胎,以最大化利用内存并且保证服务的不中断。
很显然,由于这样的需求存在,所以上 Docker 以及 Kubernetes 便成为了一件有收益且不是”脱裤子放屁“,为了用而用的事。实际上,Docker 最开始的引入,就是我为了解决 Redis 和 PostgreSQL 部署和管理的问题而设置的,docker compose 可以一键拉起来这两个数据库,通过简短的几行脚本,甚至直接挂载之前的数据库文件,就能保证 Redis 和 PG 的数据可用,如果不是 Docker,纯手工部署的 PG 迁移环境还是需要繁琐的配置账号、SQL 导出和导入吧,即便是很小版本的变化,也不敢直接拿着数据来替换数据库,Docker 使得数据的管理和维护变得异常轻松。
当然,对于 Docker 的理解也在逐步使用的过程中而日益加深,之前我一直觉得 Docker 和运维关系更大,应用最终交付的不再是 Jar 而是放在一个运行时中的 Jar,除此之外没有太大区别。但实际体验可不是这么回事,介于现在 Dev Container 已经很流行(当然,在国内可能还没有流行开),你可以将任何 Docker 看做任何环境下的运行时平台,因此我日常部署的镜像中,除了成熟且不太改动的,直接部署二进制外,其他的,都是直接部署 Git 仓库运行应用所需的工具,然后通过挂载容器映射此仓库来运行应用 —— 其好处在于,git 代码更新并 restart 容器即可实现功能迭代更新,git 撤销回退即可实现版本回退,简直不要太方便。此外,可迁移的环境带来的生产力效率也变得很高,OpenResty 中 opm 和 luarocks 包在 dev 容器中安装和 docker commit 远比在 Windows 下开发,Linux 下测试后再上传到服务器环境来的方便和健壮。
下面是我现在 CyberMe 的服务解耦化运行的容器和架构,可以说,没有 Docker,这种架构和开发模式将会困难得多:
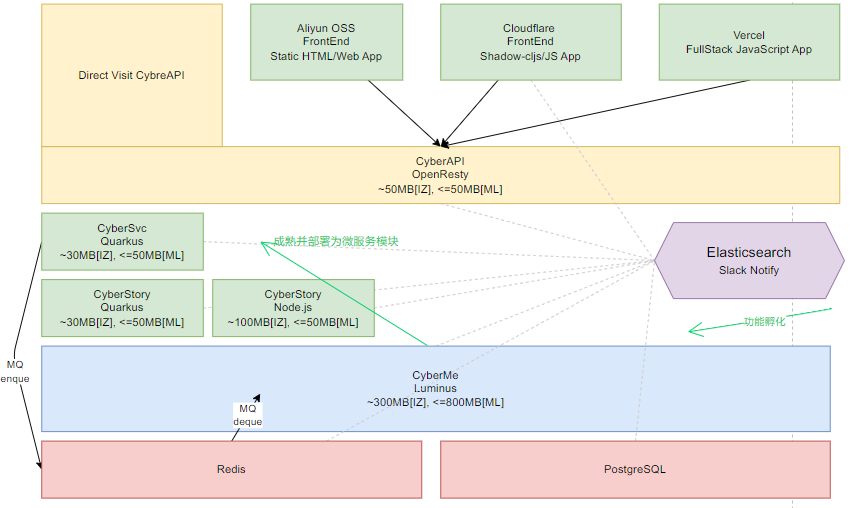
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
74797a9ab1fa cyber-svc-quarkus 0.01% 28.64MiB / 1.952GiB 1.43% 0B / 0B 173MB / 0B 10
9a2290294e8d cyber-story-quarkus 0.00% 18.36MiB / 1.952GiB 0.92% 0B / 0B 605MB / 0B 9
0c43352af7af cyber-story-node 0.00% 28.59MiB / 1.952GiB 1.43% 0B / 0B 663MB / 48.6MB 11
ea19163cbe87 cyber-me 0.27% 787MiB / 1.952GiB 39.38% 0B / 0B 280MB / 164kB 65
c72b1105cc33 cyber-api-openresty 0.00% 37.91MiB / 1.952GiB 1.90% 0B / 0B 173MB / 0B 4
a8837eaafd2e root-postgres-1 0.00% 94.07MiB / 1.952GiB 4.71% 9.62GB / 5.61GB 49.7GB / 140GB 19
8a1850b0c6bb root-redis-1 0.13% 5.992MiB / 1.952GiB 0.30% 331MB / 723MB 13.1GB / 1.59GB 5
8c6c063f4080 uptime-kuma 0.39% 139.3MiB / 1.952GiB 6.97% 5.91GB / 605MB 56.3GB / 10.8GB 12而对于 Kubernets 和 Istio 实现的微服务和服务网格,Quarkus 和 Java 在云原生下惊人的表现力(镜像大小、运行内存和启动速度,应用生态等,上述 -quarkus 微服务是基于 Kotlin 编写的,使用了 -Xmx50M 的硬性 Heap 限制)在另一篇文章中将会继续分享。还是那句话:“成功计算的钥匙并不掌握在某个程序员手上,我们需要掌握的并且应该掌握的, 是一种智慧:看到机器比第一次站在它面前时能做的更多的能力。”,我希望自己在未来还能够对待新技术能够保持一样的好奇心,探索它们所带来更多的计算的可能。