使用 Python 和 Slack 实现字幕组美剧的更新和通知
本文介绍了使用Python和Slack实现字幕组美剧更新推送的一种方法,脚本可以部署在Windows或者GNU/Linux或者macOS平台,使用计划任务或者CRON进行定时执行。你需要一个Slack的Webhook地址,用于将消息POST到你的APP -- Web、Android、iOS、watchOS以及PC、macOS均支持的Slack应用程序。
1、缘起
如果说,抬起手腕看消息相比较拿出手机、解锁后再查看消息算得上是一种进步,那么,我们需要关心的问题是,这个过程带来的不仅仅是效率的变化,更重要的是一种观念的改变。查看手机消息,顺便刷一下微博吧,嗯,前几天买的东西还没到,刷一下物流,顺便被淘宝的每日推荐/头条吸引,在评论区和人们撕,一晃,时间就过去了。小小的改变带来的改变的重要之处不是其生了几分钟时间,而是——它促进了我们关注点的变化。这是一个基础,让我们有希望从信息之中挣脱出来,在短暂的时间里做“时间的主人”。
17年中旬,当时我还没有编程经验,唯一做的就是使用VB.NET在没有任何单元调试的情况下写了一个数据库查询程序,这个软件界面漂亮、美观,虽然程序只有短短几千行,并且大部分是VS生成的,但是我依然觉得,在视觉上,这个软件达到了我的标准—如果不考虑偶然操作后报错的话,以及,这个程序完全没有解决任何实际问题这一残酷的现实的话。这不是重点。这个时候,我在Github上找到了一个很好玩的东西,叫做——Huginn,这个名字来源于希腊神话,引用一篇我自己之前写的文章:
传说有两个乌鸦,名为Huginn和Muninn,它们被视为奥丁的左肩右臂。奥丁在黎明时送出Huginn和Muninn,它们飞到世界各地,然后在晚餐时间回来,告诉奥丁它们看到和听到的一切,奥丁则赐予它们食物作为报酬。——Huginn命名的由来。
我另外写的一个软件叫做Muninn,这是一个宏大的文字游戏,其涉及目的在于连接任何我阅读到的书籍、笔记和经验。程序使用Qt和Python,目前写了2000多行,遇到了一些问题,不是那种难以解决的——却是十分繁琐的。这个程序计划写10000行,包含书籍、笔记、博客的GUI界面、添加、搜索和更改、版本修订和展示。
2、过程
今天的这个程序和Huginn有关。Huginn是理性的意思,我个人对于其意思的理解是“信息的过滤器”,正如Huginn这个框架,它从网站获取信息,并且按照一定规则进行过滤,之后通过各种方式推送通知到用户。我之前做过美剧的更新、学校通知的推送,还有现在一直在工作的天气预报推送。这个程序是运行在服务器上的,其中很多技术,包括Docker和程序使用的语言,我都不太熟悉,并且因为自己学过Pyhton,就打算使用脚本来完成这个任务。
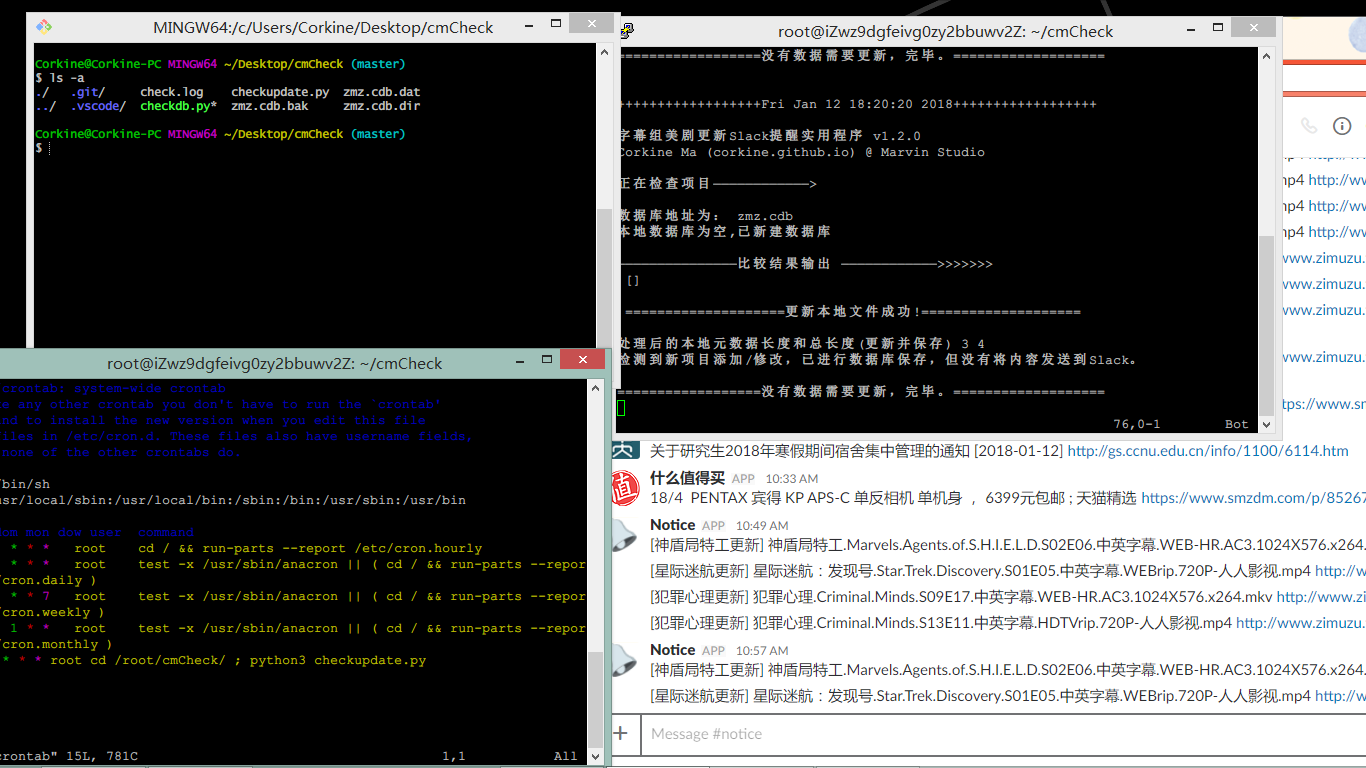
大概思路很简单,使用lxml的xpath规则从字幕组提供的XML RSS中提取内容,和本地数据库进行比较,如果本地没有的话,那么就使用webhook推送更新到Slack。程序使用cron定时执行,放在服务器上,截获输出流到文件作为日志。
当然,实际写起来却不太容易。其中遇到的几个坑,在这里说一下:
我大概花了不到10分钟就简单实现了lxml的xpath解析,以及将其中的一个内容传递到webhook并成功收到了通知。然后,花了一个上午来将这个功能写成一个类,然后花了一个下午来将这个类实现,健壮。又花了一个半天在Linux上调试,发现各种问题,进行单元测试,意识到结构的问题,进行print()打印调试,最后终于运行在服务器上。大概花了一天半的时间实现它,而它的原理,或者说一个demo,只需要10分钟就可以实现。我现在越来越觉得,任何在软件工程领域声称自己掌握了“理论”,都是扯淡,因为工程和理论的重要不同之处在于,工程的实现需要大量的实践、调试、优化、排除错误。此外,软件抄袭是一件非常难以容忍的事情,这件事表现在——如果你有明确的需求,那种精确到QAction和QListWidght的实现的需求的话,写作一个程序看起来并不是一件很辛苦的事情。但是,大多数时候,当要给独立开发者想要满足自己朦胧的需要的时候,他只知道一个大的方向,至于怎么通过软件实现,这需要经验,更需要实践。
我遇到的问题主要是将XML解析到的数据保存到shelve。这个问题的关键在于,第一次的时候,我需要单纯的将数据保存到文件中,第二次需要将两者进行比较,如何区别两者?此外,我对XML获取到的列表进行遍历,如果其没有在文件中的话,那么就添加到一个准备返回的新列表中。比较完之后,将这个列表通过Slack的Webhook发送,这没有问题。但是,如果我添加了新的需要监视的电视剧,如何保证其比较算法的健壮性?这也是小问题,更头疼的是,在缺少像数据库那种特定id标定的特性的情况下,我还需要对监视的项目进行其他操作,比如,比如我现在关注100个电视剧,那么数据库会储存100个电视剧的列表,但是,现在我只想关注10个,那么每次我需要对包含这100个电视剧的项目进行遍历,这个负担很大,尤其是当文件变大之后,此外,如何在这么多项目中定位到需要比较的项目,在没有id的情况下?我使用的数据结构是元组,元组的第一个项为电视剧的元数据信息,之后每一个项都是一个列表。之所以没有使用字典的原因是——我不想上来就使用复杂的工具,如果元组能够办到,为什么需要词典?但我忘了自己当时测试时候用的是三个电视剧项目,但实际,我需要这个类能够对多达10000个项目进行同时监控,这样问题就出现了,很显然,使用词典是一个好主意,但我写程序的初始阶段使用的是当时看起来更加方便的“元组”,这是一个“对”的选择,但是却造成了很大的负担。这种预见需要经验以及重构。
我最后还是使用元组实现了电视剧项目变化时的操作,比如突然某个电视剧位置被另一个电视剧替代了,我使用它们的地址进行比较,如果不匹配则直接更新本地文件,比如突然少了一个电视剧项目,我的方法是在比较前对比数据的个数,如果不等,则只取XML解析数据那么多的数据,其余的本地文件中的数据删掉。
这个类只有一个文件,所以我将它放在下面,程序需要安装Python以及requests库、lxml库,需要一定的xpath语法的知识,如果你打算提取不是字幕组网站的信息的话。如果是字幕组网站,如果你希望关注别的电视剧,只需要将代码最后的数据更改下就好了,所有的类、方法都有明确的注释,如果你需要推送信息到Slack,请注册Slack Team并且新建一个App,将其Webhook替换到我这里使用的,也就是类传递的这个slackurl参数。
3、尾巴
关于这个类我不打算说更多,因为它的逻辑、结构都很清晰,并且代码注释也有很多,有什么需要改进欢迎联系我:hi@marvinstudio.cn
此外,在Windows下实现的程序在Linux上有些问题,其中最影响的问题是编码,这个坑怕成为常识了都。CRON定时的设置很简单,只需要编辑/etc/crontab文件,在后面添加一行就行,*/20表示20分钟执行一次。执行多条命令使用分号隔开,建议切换到文件夹内运行,否则log文件和数据文件会保存在用户根目录下,不利于debug。
顺便说一句,我之后可能把这个程序包装成一个GUI,在GUI调用的时候自动查询更新,但是那样的话——对于新手来说很友好,不过引出了一个哲学问题——为什么我不去收藏的网站看是否更新而是要使用你这个打包好的二进制GUI文件来看呢?GUI打包后运行是方便了,不过调整起来却很麻烦,比如识别文件规则的调整。这个问题我无法解决,因此我选择了靠近程序这一边,也就是仅提供程序,因为一旦要写GUI的话,我很容易写成一个简化版的Huginn框架,这样重复造轮子是效率浪费,并且,我自己服务器上就跑着Huginn,写这个程序只是想看看自己从无到有写一个类的时候,是如何着手的,当然,更多的原因是闲的无聊,就比如之前我等快递的时候使用API写了一个快递查询GUI程序一样。
4、代码
程序如下:
#/usr/bin/env python3
# -*- coding:utf8 -*-
import requests
import lxml.etree
import json
import pickle,traceback,shelve,time,sys
__title__ = "字幕组美剧更新Slack提醒实用程序"
__author__ = "Corkine Ma (corkine.github.io) @ Marvin Studio"
__version__ = '1.2.0'
__log__ = """Linux下编码为UTF8,和Windows的ANSI不同,因此在写入Log时可能出现一些问题,造成通知问题
0.5.0 2018年1月10日 添加此程序
1.0.0 2018年1月12日 修正了Linux下的文件编码问题,修正了新项目添加推送到Slack的问题。仍存在的Bug有:从本地数据库检索可能有问题
1.2.0 2018年1月12日 修正了增删请求数据造成的本地数据更新问题。解决了没有数据库文件时检索数据特定键值出现的错误。
"""
class ZMZChecker:
"""检查字幕组网站的某个电视剧的RSS订阅是否更新,如果更新则推送更新项目到我的Slack中。
判断的标准是将RSS的XML文件和本地的数据库文件迭代比较。传递的参数有两个,分别是要检索的数据和Slack的Webhook。
1、元数据:元数据由多个电视剧项目组成的元组构成,电视剧项目同样是一个元组,包含三个参数,一是自定义
通知(可以为空),二是RSS地址,三是当前电视剧详情页地址(可以为空)。
2、Slack的Webhook:前往Slack官方网站注册Slack Team,然后新建一个App,获得Webhook地址,你可以自定义
该App的通知位置以及通知图标,将此Webhook地址作为参数传递。进一步的自定义传递你可以修改ZMZChecker的uploadtoSlack方法。
"""
def __init__(self,metadata,slackurl="",address="zmz.cdb",log="check.log"):
self.metadata = metadata
self.dirty = False
self.delerr = False
self.newitem = False
self.url = slackurl
self.goCheck(address=address,log=log)
def goCheck(self,address="",log=""):
'''进行项目检查,结果输出到标准流,你可以在这里自定义截获输出到某文件进行保存。'''
tmp_out = sys.stdout
tmp_err = sys.stderr
if log == "":
raise ValueError("LOG文件无法打开,请检查程序所在文件夹写权限")
sys.stdout = open(log,'a')
sys.stderr = open(log,"a")
print("\n++++++++++++++++++%s++++++++++++++++++\n"%str(time.ctime()))
print("%s v%s \n%s\n"%(__title__,__version__,__author__))
print("正在检查项目————————————>\n")
if address == "":
raise ValueError("本地数据库为空或无法打开,请检查写权限。")
# 解析XML获取当前RSS信息
webdb = (self.metadata,)
for item in self.metadata:
rss,webaddress = item[1],item[2]
itemlist = self.getInfo(rss)
webdb += (itemlist,)
# print("互联网库为",webdb)
# 和本地数据进行比较
# address = "zmz.cdb"
print("数据库地址为:",address)
outlist = self.checkUpdate(address,webdb)
print("\n———————————————比较结果输出 ————————————>>>>>>> \n",outlist)
# 如果发生改变,则使用webhook发送到Slack并更新本地数据库,否则结束流程。
if self.dirty != False and self.newitem == False:
for item in outlist:
text_title = item[1][0] +" "+ item[0]
webaddress = item[1][2]
text = text_title + " " +webaddress
self.uploadtoSlack(text)
print("正在更新——————————> ",text_title)
self.updateLocalDB(address,webdb)
print("通知已发送。")
else:
if self.newitem == True or self.delerr == True:
self.updateLocalDB(address,webdb)
print("检测到新项目添加/修改,已进行数据库保存,但没有将内容发送到Slack。")
print("\n==================没有数据需要更新,完毕。===================\n")
sys.stdout.close()
sys.stderr.close()
sys.stdout = tmp_out
sys.stderr = tmp_err
def getInfo(self, rss=""):
'''对网站地址进行解析,获得XML文件,根据XPATH规则获取条目,以列表形式返回'''
response = requests.get(rss)
content = response.content
xml = lxml.etree.XML(content)
clist = xml.xpath('//channel/item/title')
rlist = []
for x in clist:
if "中英字幕" in x.text:
rlist.append(x.text)
return rlist
def uploadtoSlack(self, text = ""):
'''将文本打包为json格式,使用Webhook的方式POST到Slack的Webhook,返回状态码'''
url = self.url
payload = {'text':text}
data = json.dumps(payload)
response = requests.post(url, data=data)
return response
def checkUpdate(self, address="", webdb = None):
'''传递两个参数,分别是本地数据地址,以及要进行比较的数据。遍历列表检查更新,如果发现要比较的数据不存在于本地数据,
则添加到一个列表,最后将其返回'''
try:
db_local = shelve.open(address)
db = db_local["info"]
# print("+++++++++++++++++++++++++++++OLDDB",db)
db_local.close()
except Exception as _err:
print("本地数据库为空,已新建数据库")
db = db_local["info"] = webdb
self.newitem = True
db_local.close()
return []
# 此部分目的在于更新本地数据库,删除请求数据中没有的,但是本地数据中有的条目。
number_web = len(webdb[0])
print("在线元数据长度:",number_web)
number_local = len(db[0])
print("本地元数据长度:",number_local)
if number_local > number_web:
print("检测到本地数据库存在无效条目,已删除。")
db_meta = db[0][:number_web]
db_head = db[1:number_web+1]
db = (db_meta,) + db_head
self.delerr = True
print("处理后的在线元数据长度和总长度",len(webdb[0]),len(webdb))
print("处理后的本地元数据长度和总长度(未保存前的状态)",len(db[0]),len(db))
outlist = []
for id_ in range(number_web):
id_ = id_ + 1
try:
list_local = db[id_]
if db[0][id_-1][1] != webdb[0][id_-1][1]:
raise ValueError("项目不匹配")
except:
self.newitem = True #刚添加RSS的时候肯定没更新,所以必然获得了所有的数据,这个更新量发送到Slack
# 是很恐怖的,所以直接跳过保存到Slack这一步,下次再更新的时候才推送通知到Slack。
list_local = ''
list_web = webdb[id_]
for item_web in list_web:
if not item_web in list_local:
outlist.append((item_web,webdb[0][id_ - 1]))
self.dirty = True
return outlist
def updateLocalDB(self, address = "", webdb = None):
'''更新本地文件,传入参数为本地文件地址以及要写入的数据'''
try:
db = shelve.open(address)
db["info"] = webdb
except Exception as _err:
print("Save Pickle Failed. \n%s"%_err)
finally:
db.close()
print("\n","="*20 + "更新本地文件成功!" + "="*20,"\n")
print("处理后的本地元数据长度和总长度(更新并保存)",len(webdb[0]),len(webdb))
if __name__ == "__main__":
SHIELD = "[神盾局特工更新]","http://diaodiaode.me/rss/feed/30675","http://www.zimuzu.tv/resource/30675"
DESCOVERY = "[星际迷航更新]","http://diaodiaode.me/rss/feed/35640","http://www.zimuzu.tv/resource/35640"
MIND = "[犯罪心理更新]","http://diaodiaode.me/rss/feed/11003","http://www.zimuzu.tv/resource/11003"
TIANFU = "[天赋异禀更新]","http://diaodiaode.me/rss/feed/35668","http://www.zimuzu.tv/resource/35668"
METADATA = (SHIELD,DESCOVERY,MIND)
# METADATA = (SHIELD,DESCOVERY,MIND,TIANFU)
# print(METADATA)
# data = ()
# for item in open("checkitem.txt",'r'):
# item = item.replace("\n",'')
# if item != None and item != "" and len(item) != 0:
# items = item.split(",")
# if len(items) != 3:
# raise ValueError("数值不匹配")
# else:
# items_set = ()
# for x in items:
# items_set += (x,)
# data += (items_set,)
# # print(data)
# # 需要注意,checkitem文件逗号为英文逗号,并且逗号前后没有间隔,换行符之前没有空白。
# # print("相等?",data == METADATA)
# METADATA = data
checker = ZMZChecker(metadata=METADATA,slackurl="https://hooks.slack.com/services/XXXXXXXQs")